Category: Uncategorized
Testing microservices. Review of Building Microservices.
A few weeks ago I came across an awesome book “Building Microservices” by Sam Newman. Author covers a lot of useful topics about microservices such as testing, deployment, monitoring etc. So, I decided to write my review for the most interesting parts for me and take out notable quotes from this books.
Background
“A key driver to ensuring we can release our software frequently is based on the idea that we release small changes as soon as they are ready.”
There are a lot approaches how to test monolithic application. However, distributed system bring new impediments. Every change within one microservice can impact on other microservices and eventually breaks the system. How to be sure that microservice is ready for release and the whole system won’t be broken? Which tests should be written and which test strategies should be used?
Solution
Author describes 3 levels of tests:
Unit tests
These are tests that typically test a single function or method call. The tests generated as a side effect of test-driven design (TDD). Done right, they are very, very fast, and on modern hardware you could expect to run many thousands of these in less than a minute. The prime goal of these tests is to give us very fast feedback about whether our functionality is good.
Integration Tests (Service)
The reason we want to test a single service by itself is to improve the isolation of the test to make finding and fixing problems faster. To achieve this isolation, we need to stub out all external collaborators so only the service itself is in scope
End-to-End
End-to-end tests are tests run against your entire system. These tests cover a lot of production code. So when they pass, you feel good: you have a high degree of confidence that the code being tested will work in production
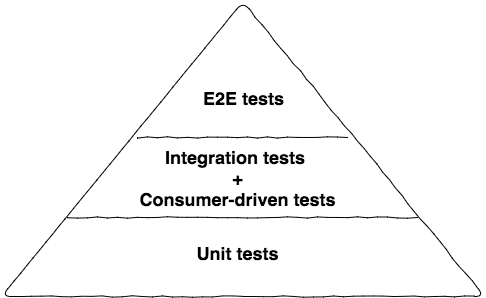
Sam explains the idea of testing pyramid: “As you go up the pyramid, the test scope increases, as does our confidence that the functionality being tested works. On the other hand, the feedback cycle time increases as the tests take longer to run, and when a test fails it can be harder to determine which functionality has broken.”
But how to implement end-to-end tests? We need to deploy multiple services together and then run a test against all of them. Usually, there is a separate application (extra microservice) which contains e2e tests. The system is a black-box for such tests. And I will suggest to use BDD scenarios and appropriate frameworks (e.g. cucumber, jbehave etc).
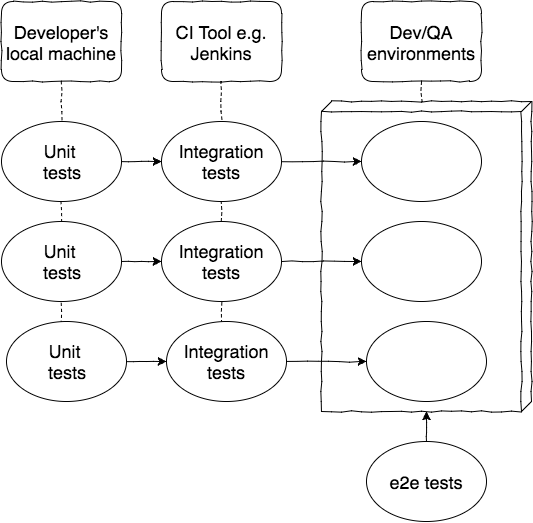
In that case, business provides BDD scenarios, QA team writes BDD tests and runs them against the black-box. Thereby developers can change the structure of system in future without impact on these tests.
However, there is a warning from author – “Be careful with amount of end-to-end tests. Show me a codebase where every new story results in a new end-to-end test, and I’ll show you a bloated test suite that has poor feedback cycles and huge overlaps in test coverage.”
Useful links
- Building Microservices by Sam Newman
- http://stackoverflow.com/a/7876055

microservices and integration
Integration technologies for microservices. Review of Building Microservices.
A few weeks ago I came across an awesome book “Building Microservices” by Sam Newman. Author covers a lot of useful topics about microservices such as testing, deployment, monitoring etc. So, I decided to write my review for the most interesting parts for me and take out notable quotes from this books.
Background
The next useful topic is communication between microservices. Authors describes common requirements for ideal integration technology, compares asynchronous and synchronous communication, considers different protocols such as RPC, REST and ActiveMQ etc
Solutions
Requirements
There are some generic requirements for integration technology:
- Avoid breaking changes – if a microservice adds new fields to data it sends out, existing consumers shouldn’t be impacted. Here we can recollect the Postel’s law “Be liberal in what you accept, and conservative in what you send”.
- Technology agnostic – means avoiding integration technology that dictates what technology stacks we can use.
- Simple for consumers – if you decide to use REST there are a lot of different libraries for different frameworks and languages. Or as another solution you can provide a client library for your APIs.
- Hide Internal implementation – any integration technology that pushes us to expose internal representation detail should be avoided
Integraion via Shared Database
The most commonly used type of integration is Shared Database. But Sam says a good phrase “Database integration makes it easy for services to share data, but does nothing about sharing behavior. Because of that, author insists to avoid database integration at all costs.”
Integraion via REST
Strongly consider REST as a good starting point for request/response integration. There are a lot of frameworks that help us create RESTFul web services.
Integraion via Event-based
Author emphasizes the following benefits – “Event-based model provides highly decoupled collaboration. The business logic is not centralized into core brains, but instead pushed out more evenly to the various collaborators. The client that emits an event doesn’t have any way of knowing who or what will react to it, which also means that you can add new subscribers to these events without the client ever needing to know.”
Libraries
A good example is well-known Netflix company. Netflix’s libraries handle service discovery, failure modes, logging, and other aspects that aren’t actually about the nature of the service itself.
“Decide whether or not you are going to insist on the client library being used, or if you’ll allow people using different technology stacks to make calls to the underlying API.”
How to create a maven java project
If you need to create a maven project, you can generate it using maven “maven–archetype–quickstart”. Here is an example how to use this arhetype:
| #!/usr/bin/env bash | |
| mvn archetype:generate \ | |
| -DarchetypeArtifactId=maven-archetype-quickstart \ | |
| -DgroupId=com.agritsik.samples.app \ | |
| -DartifactId=test-app | |
| # mvn package && java -cp target/test-app-1.0-SNAPSHOT.jar com.agritsik.samples.app.App | |
| # Output example: Hello World! |
As a result you will get the following structure of your project:

Default structure for the maven project
How to wait for another docker container startup
There is a popular situation when you have an application in one docker container and that application uses mysql (or any other database, rabbitmq etc) from another container. And you need to start your app when all other containers are up and running and listening on the concrete port.
The most straightforward solution is using netcat utility which allows reading from and writing to network connections using TCP and UDP protocol. Here is an example:
| # note, netcat utility should be installed in docker container | |
| while ! nc -z DB 3306; do sleep 3; done | |
| # DB is available here, so we can start our applicaiton | |
| # java -jar /app.jar |
Where ‘-z’ option specifies that nc should just scan for listening daemons, without sending any data to them

Is a docker container up and running?
How to remove all docker containers and images
Here is a simple but at the same time a useful .sh script which I use in all my projects for cleaning up my docker containers and unused docker images.
| #!/usr/bin/env bash | |
| # Remove all stopped containers | |
| docker rm -v $(docker ps -a -q) | |
| # Remove all untagged images | |
| docker rmi $(docker images | grep "^<none>" | awk "{print $3}") |
The very first command removes all containers. Note that docker ps command displays only running containers. If you add “-a” param, docker ps command returns all stopped and running containers. Using “-q” param we ask docker to display container IDs only.
The second command removes all untagged (i.e. replaced by the image with the same version) images.
How to remove docker containers and images?
